19. Introduction to Machine Learning#
20. Key ideas from the video#
20.1. Training#
The model is only updated during training and then its “memory” is fixed to provide consistent predictions.
20.2. Learning#
The model learns to improve its predictions given feedback from the training data. When incorrect, the weights and biases in the model are adjusted deliberately to reduce error. With spaCy, training continues until the model is no longer improving its predictions.
20.3. Classification Metrics#
Accuracy and loss. As the model trains, the loss (a measure of incorrect predictions) should decrease, while accuracy (percentage of correct predictions) should increase.
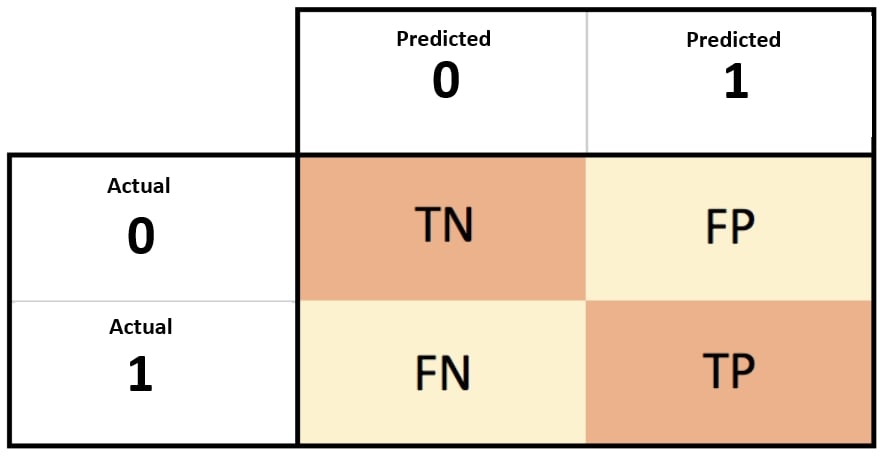
True positives (TP): The prediction was yes, and the true value is yes
False positives (FP): The prediction was yes, but the true value was no
False negatives (FN): The prediction was no, but the true value is yes
Precision is a measure of how often the model’s predictions were correct. It is the number of correct predictions divided by the total number of predictions made by the model:
TP/(TP+FP)Recall is a similar measure, but uses false negatives
TP/(TP+FN)F1 score, the weighted average of precision and recall
20.4. Underfitting and overfitting#
Underfitting describes a model that isn’t learning how to make good predictions on your data. It may need more data, better data, more training, better feature engineering or model architecture.
Overfitting describes a model that performs very well with the training data but is unable to make good predictions with new or unseen data.
20.5. Data splits#
Training, validation and test data.
Training and validation are used during training. The validation set is checked to measure if the model is improving. The test set is needed to evaluate the model after training. It’s data that the model has never seen, so it’s a good measure of its ability to reason about new data.
20.6. Label distribution#
When we run spacy debug data you’ll be able to identify labels in your dataset with a small number of examples. In such a case, we need to be careful that a sufficient number of examples are present in the training, validation, and test sets.
20.7. Embeddings#
A word or token embedding is a numerical representation of a word or token. You may also hear them referred to as vectors. A vector is a one dimensional array such as [0,0,0,0,1].